leveldb 中常用的数据结构 1. Slice Slice 是 leveldb 中使用最为频繁的数据结构,不管是 Write Batch,还是构建 SSTable,都需要 Slice 的重度参与。这里的 Slice 并不是 Go 语言中的切片,而是封装的 string 类型。
C++ 中的 std::string 只提供了简单的 push_back、pop_back 等方法,诸如 starts_with、remove_prefix 等方法都没有提供。因此,leveldb 使用 char * 自行封装了 string 对象,以满足功能需要。
Slice 中的成员变量只有两个,一个是 char 类型的字符指针,另一个则是字符串的长度。此外,Slice 本身并不负责内存分配,只是简单地接收外部传入的指针对象。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class LEVELDB_EXPORT Slice {public : Slice (const std::string& s) : data_ (s.data ()), size_ (s.size ()) {} Slice (const char * s) : data_ (s), size_ (strlen (s)) {} void remove_prefix (size_t n) data_ += n; size_ -= n; } std::string ToString () const { return std::string (data_, size_); } bool starts_with (const Slice& x) const return ((size_ >= x.size_) && (memcmp (data_, x.data_, x.size_) == 0 )); } private : const char * data_; size_t size_; };
Slice 的实现并不复杂,甚至没有提供内存分配机制,只是简单地进行了一个封装,但却是 leveldb 中最为重要的数据结构。
2. Status 在 Web 开发中,由于 HTTP 状态码数量有限,不能够完全地表达出调用 API 的结果,因此通常都会采用自定义 error_code 的方式实现,比如微信公众号的全局错误返回码: 全局返回码说明 ,一个统一的返回状态能够有效地降低后期运维成本。leveldb 并没有使用 Linux Kernel 的错误返回,而是使用 Status 类来制定统一的返回状态。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class LEVELDB_EXPORT Status {private : enum Code { kOk = 0 , kNotFound = 1 , kCorruption = 2 , kNotSupported = 3 , kInvalidArgument = 4 , kIOError = 5 }; const char * state_; };
leveldb 一共定义了 6 种状态,内部使用枚举类实现,每一个返回状态都会有对应的 2 个方法,一个是构造返回状态,另一个则是判断状态。以 kNotFound 为例:
1 2 3 4 5 6 7 static Status NotFound (const Slice& msg, const Slice& msg2 = Slice()) return Status (kNotFound, msg, msg2); } bool IsNotFound () const return code () == kNotFound; }
可以看到,方法名和状态名称之间是强耦合的,也就是说我们无法在不改变 Status 定义的前提下对其进行拓展,算是一个小小的缺点。
简单地看一下 Status 的构造函数实现,通过状态码和错误信息构造 Status 属于私有方法,只能由 NotFound()、Corruption()、InvalidArgument() 等方法调用,这又限制了我们自行拓展 Status 的能力。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 Status::Status (Code code, const Slice& msg, const Slice& msg2) { const uint32_t len1 = static_cast <uint32_t >(msg.size ()); const uint32_t len2 = static_cast <uint32_t >(msg2.size ()); const uint32_t size = len1 + (len2 ? (2 + len2) : 0 ); char * result = new char [size + 5 ]; std::memcpy (result, &size, sizeof (size)); result[4 ] = static_cast <char >(code); std::memcpy (result + 5 , msg.data (), len1); if (len2) { result[5 + len1] = ':' ; result[6 + len1] = ' ' ; std::memcpy (result + 7 + len1, msg2.data (), len2); } state_ = result; }
Status 的结构如下图所示,在内部只需要使用 state_[4] 即可获得 Status 的具体状态:
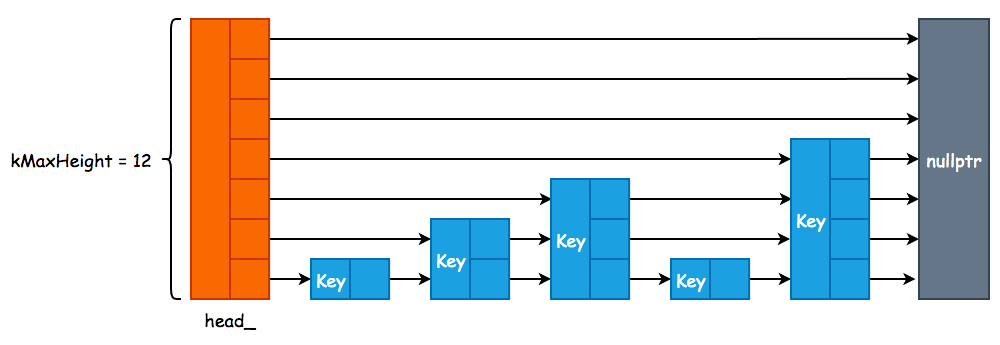
3. Skip List Memory Table 由 Skip List 实现,由于 leveldb 在对 Key 进行修改和删除操作时,采用的是追加方式,因此 Skip List 只需要实现插入和查找两个方法即可:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 template <typename Key, class Comparator >class SkipList {private : struct Node ; public : explicit SkipList (Comparator cmp, Arena* arena) void Insert (const Key& key) bool Contains (const Key& key) const private : enum { kMaxHeight = 12 }; Arena* const arena_; Node* const head_; };
Skip List 的核心结构为 Node,其内部采用原子变量来进行指针的相关操作,因此,leveldb 中的 Skip List 是线程安全的,并且使用的是无锁实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 template <typename Key, class Comparator >struct SkipList <Key, Comparator>::Node { explicit Node (const Key& k) : key(k) { Key const key; Node* Next (int n) { return next_[n].load (std::memory_order_acquire); } void SetNext (int n, Node* x) next_[n].store (x, std::memory_order_release); } private : std::atomic<Node*> next_[1 ]; };
Skip List 的大致结构如下,和 Redis 中跳跃表不同的是,leveldb 并没有使用 prev 指针,因为根本就用不到:
4. LRUCache 为了优化查询效率,leveldb 自行实现了一个标准的 LRU Cache,即哈希表+双向链表,并且 leveldb 选择了自行实现哈希表,并没有使用 std::unordered_map,同时使用了 port::Mutex 来保证 LRU Cache 的并发安全性。port::Mutex 其实就是对 std::mutex 的简单封装。